데이터프레임은 2차원 배열이다.
행과 열로 만들어지는 2차원 배열 구조는 엑셀과 RDBMS등 다양한 컴퓨터 분양에서 사용중
데이터프레임의 열은 각각 시리즈 객체.
시리즈를 열벡터(vector)라고 하면, 데이터프레임은 여러개의 열벡터들이 같은 행 인덱스를 기준으로 줄지어 결합된 2차원 벡터 또는 행렬(matrix)
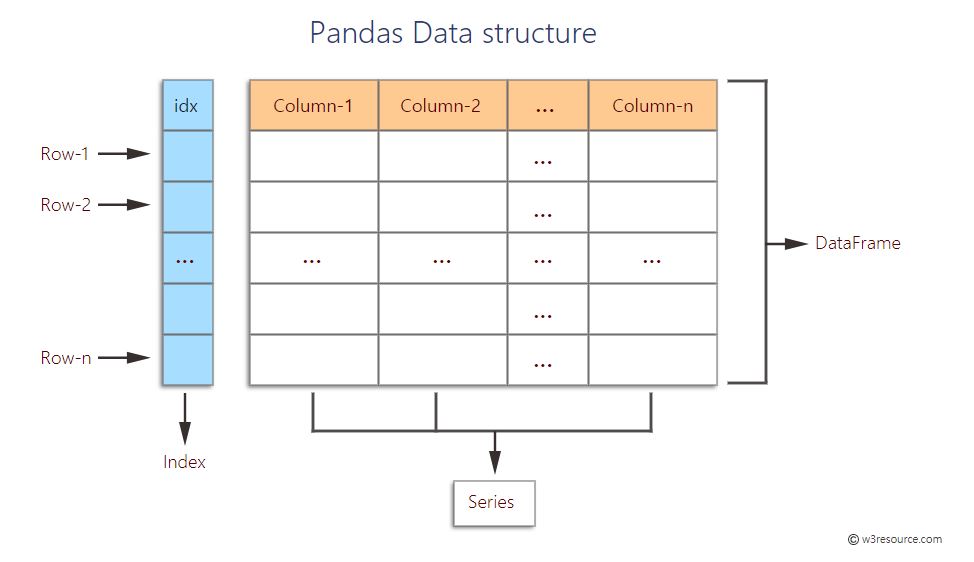
데이터프레임은 행과 열을 나타내기 위해 두 가지 종류의 주소를 사용
행 인덱스(row index) 와 열 이름(column name 또는 column label)
데이터프레임의 열은 공통의 속성을 갖는 일련의 데이터를 나타내고,
행은 개별 관측대상에 대한 다양한 속성 데이터들의 모음인 레코드가 된다.
데이터프레임 만들기
데이터프레임을 만들기 위해서는 같은 길이(원소의 개수가 동일한)의 1차원 배열 여러 개가 필요
-> 여러 개의 시리즈를 모아 놓은 집합으로 이해 하면 쉬움
데이터프레임 변환 : pandas.DataFrame(딕셔너리 객체)
import pandas as pd
#열 이름을 key로 하고, 리스트를 value로 갖는 딕셔너리 정의(2차원 배열)
dict_data = {'c0':[1,2,3], 'c1':[4,5,6], 'c2':[7,8,9], 'c3':[10,11,12], 'c4':[13,14,15]}
#판다스 DataFrame() 함수로 딕셔너리를 데이터프레임으로 변환 후 변수 df에 저장
df = pd.DataFrame(dict_data)
#출력
print(type(df))
print(df)
-------------------------------------------------------------------------------------------
<실행 결과>
<class 'pandas.core.frame.DataFrame'>
c0 c1 c2 c3 c4
0 1 4 7 10 13
1 2 5 8 11 14
2 3 6 9 12 15행 인덱스 / 열 이름 설정
데이터프레임의 구조적 특성 때문에 2차원 배열 형태의 데이터를 데이터프레임으로 변환하기 쉽다.
2차원 배열을 DataFrame() 함수 인자로 전달하여 데이터프레임으로 변환할 때 행 인덱스와 열 이름 속성을 직접 지정할 수 있다.
행 인덱스/열 이름 설정 : pandas.DataFrame(2차원 배열, index=행 인덱스 배열, columns=열 이름 배열)
df = pd.DataFrame([[15, '남', '덕명중'], [17, '여', '수리중']],
index = ['준서','예은'],
columns=['나이', '성별','학교'])
print(df)
print(df.index)
print(df.columns)
-----------------------------------------------------------------------------------------------
<실행 결과>
나이 성별 학교
준서 15 남 덕명중
예은 17 여 수리중
Index(['준서', '예은'], dtype='object')
Index(['나이', '성별', '학교'], dtype='object')
행 인덱스 변경 : DataFrame 객체.index = 새로운 행 인덱스 배열
열 이름 변경 : DataFrame 객체.columns = 새로운 열 이름 배열
#행 인덱스, 열 이름 변경
df.index=['학생1', '학생2']
df.columns=['연령', '남녀', '소속']
print(df)
print(df.index)
print(df.columns)
-----------------------------------------------------------------------------------------------
<실행 결과>
연령 남녀 소속
학생1 15 남 덕명중
학생2 17 여 수리중
Index(['학생1', '학생2'], dtype='object')
Index(['연령', '남녀', '소속'], dtype='object')
데이터 프레임에 rename() 메소드를 적용하면 행 인덱스 또는 열 이름 일부를 선택하여 변경 할 수 있다.
단, 원본 객체를 직접 수정하는 것이 아니라 새로운 데이터프레임 객체를 반환한다.
원본 객체를 변경하려면 inplace=True 옵션을 적용한다.
행 인덱스 변경 : DataFrame 객체.rename(index = {기존 인덱스 : 새 인덱스, ...})
열 이름 변경 : DataFrame 객체.rename(columns = {기존 이름: 새 이름, ...})
df = pd.DataFrame([[15, '남', '덕명중'], [17, '여', '수리중']],
index = ['준서','예은'],
columns=['나이', '성별','학교'])
print(df)
df.rename(index={'준서':'학생1', '예은':'학생2'}, inplace=True)
df.rename(columns={'나이':'연령', '성별':'남녀', '학교':'소속'}, inplace=True)
print(df)
-----------------------------------------------------------------------------------------------
<실행 결과>
나이 성별 학교
준서 15 남 덕명중
예은 17 여 수리중
연령 남녀 소속
학생1 15 남 덕명중
학생2 17 여 수리중
행 / 열 삭제
행을 삭제하는 명령은 drop()
행을 삭제할 때 축(axis) 옵션으로 axis=0을 입력하거나 별도로 입력하지 않는다.
축 옵션으로 axis=1을 입력하면 열을 삭제
동시에 여러 개의 행 또는 열을 삭제 하려면 리스트 형태로 입력
drop() 메소드는 기존 객체를 변경하지 않고 새로운 객체를 반환한다.
직접 변경 하기 위해서는 inplace = True 옵션을 추가한다.
행 삭제 : DataFrame 객체.drop(행 인덱스 또는 배열, axis=0)
열 삭제 : DataFrame 객체.drop(열 이름 또는 배열, axis=1)
행 삭제
exam_data = {'수학' : [90,80,70],
'영어' : [98,89,95],
'음악' : [85,95,100],
'체육' : [100,90,90]}
df = pd.DataFrame(exam_data,index=['서준','우현','인아'])
print(df)
#데이터프레임 df를 복제 하여 df2에 저장, df2의 1개 행 삭제
df2 = df[:].copy()
df2.drop('우현', inplace=True)
print(df2)
#데이터프레임 df를 복제하여 df3에 저장, df3의 2개 행 삭제
df3 = df[:].copy()
df3.drop(['우현','인아'], inplace=True)
print(df3)
-----------------------------------------------------------------------------------------------
<실행 결과>
수학 영어 음악 체육
서준 90 98 85 100
우현 80 89 95 90
인아 70 95 100 90
수학 영어 음악 체육
서준 90 98 85 100
인아 70 95 100 90
수학 영어 음악 체육
서준 90 98 85 100열 삭제
print(df)
#데이터프레임 df를 복제 하여 df4에 저장, df4의 1개 열 삭제
df4 = df[:].copy()
df4.drop('수학', axis=1, inplace=True)
print(df4)
#데이터프레임 df를 복제하여 df5에 저장, df5의 2개 열 삭제
df5 = df[:].copy()
df5.drop(['영어','음악'], axis=1, inplace=True)
print(df5)
-----------------------------------------------------------------------------------------------
<실행 결과>
수학 영어 음악 체육
서준 90 98 85 100
우현 80 89 95 90
인아 70 95 100 90
영어 음악 체육
서준 98 85 100
우현 89 95 90
인아 95 100 90
수학 체육
서준 90 100
우현 80 90
인아 70 90
'머신러닝 > Pandas' 카테고리의 다른 글
| 데이터프레임 기본 [2/2] (0) | 2022.04.27 |
|---|---|
| 판다스 기초 (0) | 2022.04.22 |